UMPNet: Universal Manipulation Policy Network for Articulated Objects
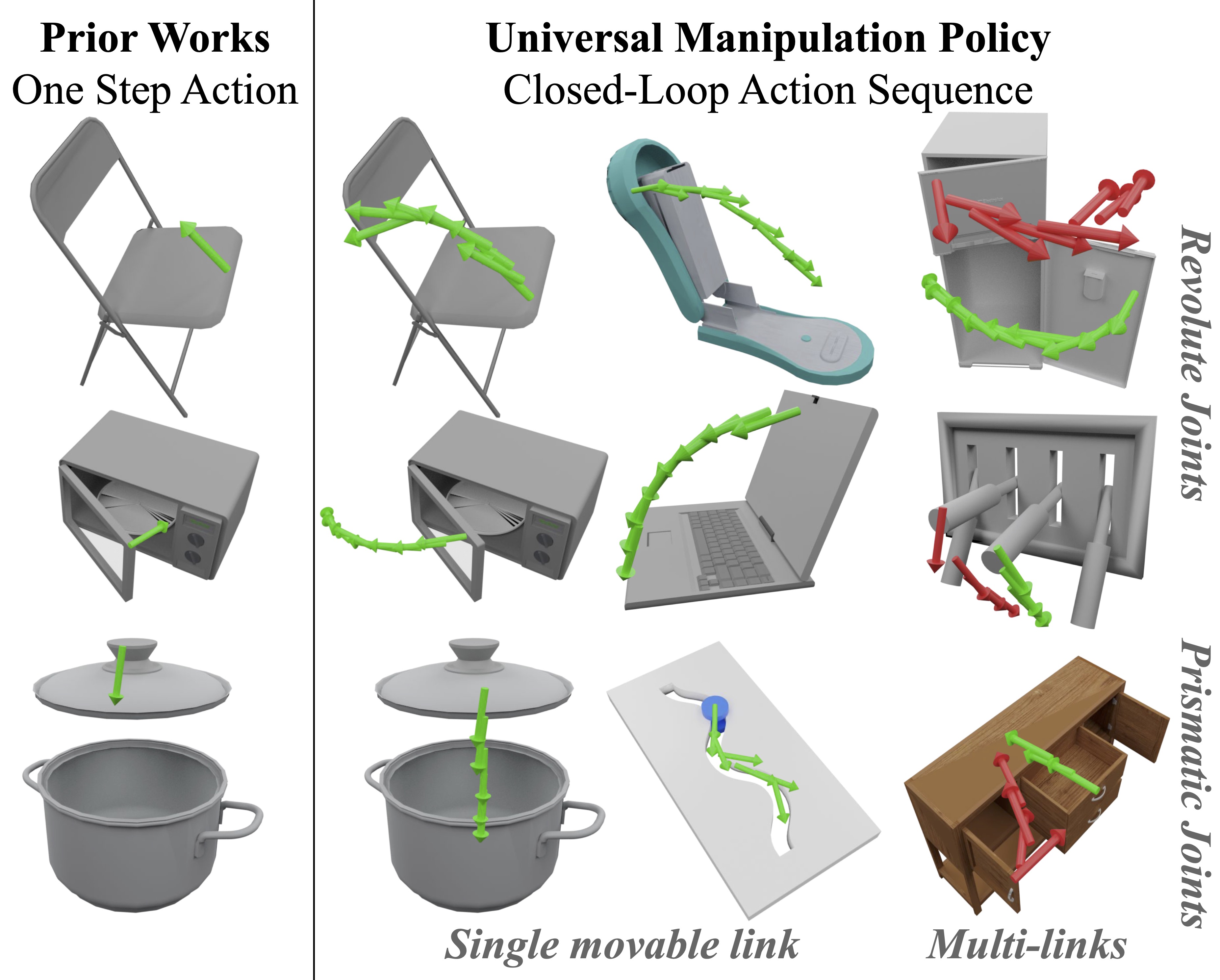
We introduce the Universal Manipulation Policy Network (UMPNet) -- a single image-based policy network that infers closed-loop action sequences for manipulating arbitrary articulated objects. To infer a wide range of action trajectories, the policy supports 6DoF action representation and varying trajectory length. To handle a diverse set of objects, the policy learns from objects with different articulation structures and generalizes to unseen objects or categories. The policy is trained with self-guided exploration without any human demonstrations, scripted policy, or pre-defined goal conditions. To support effective multi-step interaction, we introduce a novel Arrow-of-Time action attribute that indicates whether an action will change the object state back to the past or forward into the future. With the Arrow-of-Time inference at each interaction step, the learned policy is able to select actions that consistently lead towards or away from a given state, thereby, enabling both effective state exploration and goal-conditioned manipulation.
Paper
Latest version: arXiv
Robotics and Automation Letters (RA-L) / ICRA 2022

Team



Columbia University in the City of New York
BibTeX
@article{xu2022umpnet,
title={UMPNet: Universal manipulation policy network for articulated objects},
author={Xu, Zhenjia and Zhanpeng, He and Song, Shuran},
journal={IEEE Robotics and Automation Letters},
year={2022},
publisher={IEEE}
}Technical Summary Video
Open-ended State Exploration Results
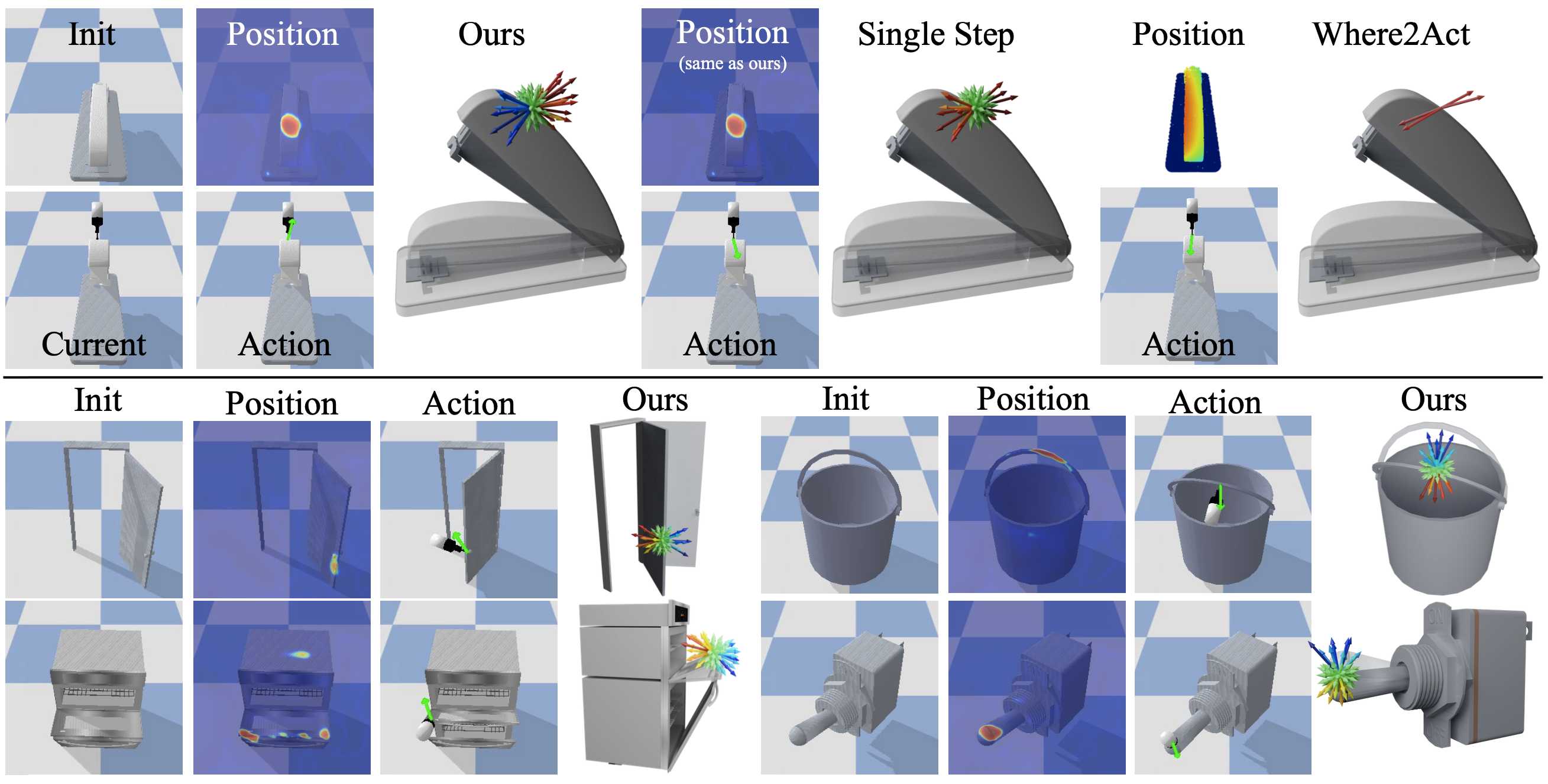
Arrow length indicates the inferred distance value, color indicates the inferred AoT label. We visualized the uniform samples to better illustrate the AoT distribution. All methods are able to choose a suitable position, however, both SingleStep and Where2Act cannot distinguish between actions that are moving away from or back to initial state (all directions are red) leading to inefficient exploration. In contrast, UMPNet is able to infer the correct AoT labels, hence, select the correct action to explore novel states.
Goal-conditioned Manipulation Results
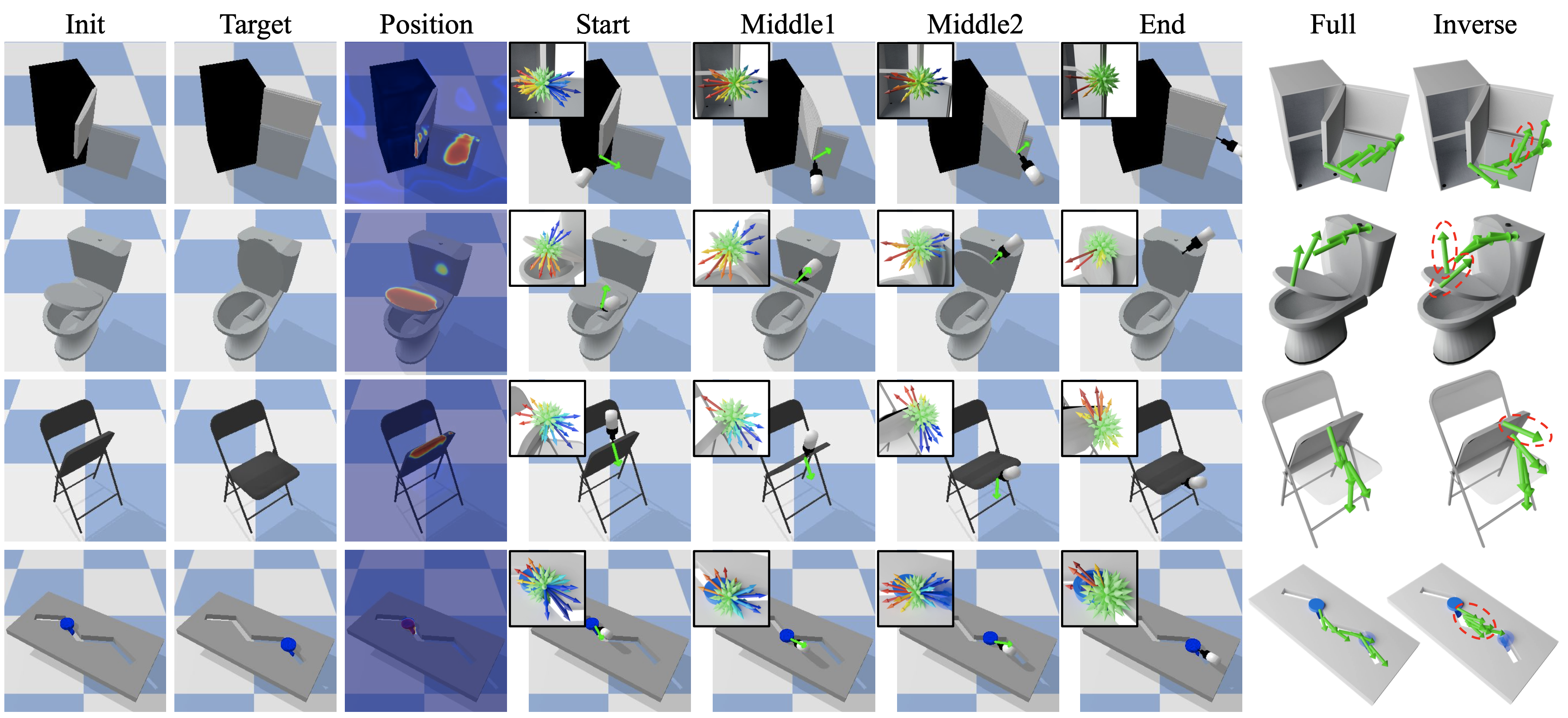
At the beginning or in the middle of a trajectory, the action candidates have positive (red) and negative (blue) AoT labels. To move toward the goal, the policy selects the action with the largest distance prediction and a negative AoT label (the longest blue arrow) to execute. When reaching the goal state (current and goal state are similar), the AoT labels turn non-negative for all actions since all actions will either make no change or move further away from the goal state. The [Inverse] model (right-most column) often chooses sub-optimal action directions (highlighted by red dash circles) at the beginning of the interaction sequence where the current observation is far away from the goal states.
Articulation Structure Inference
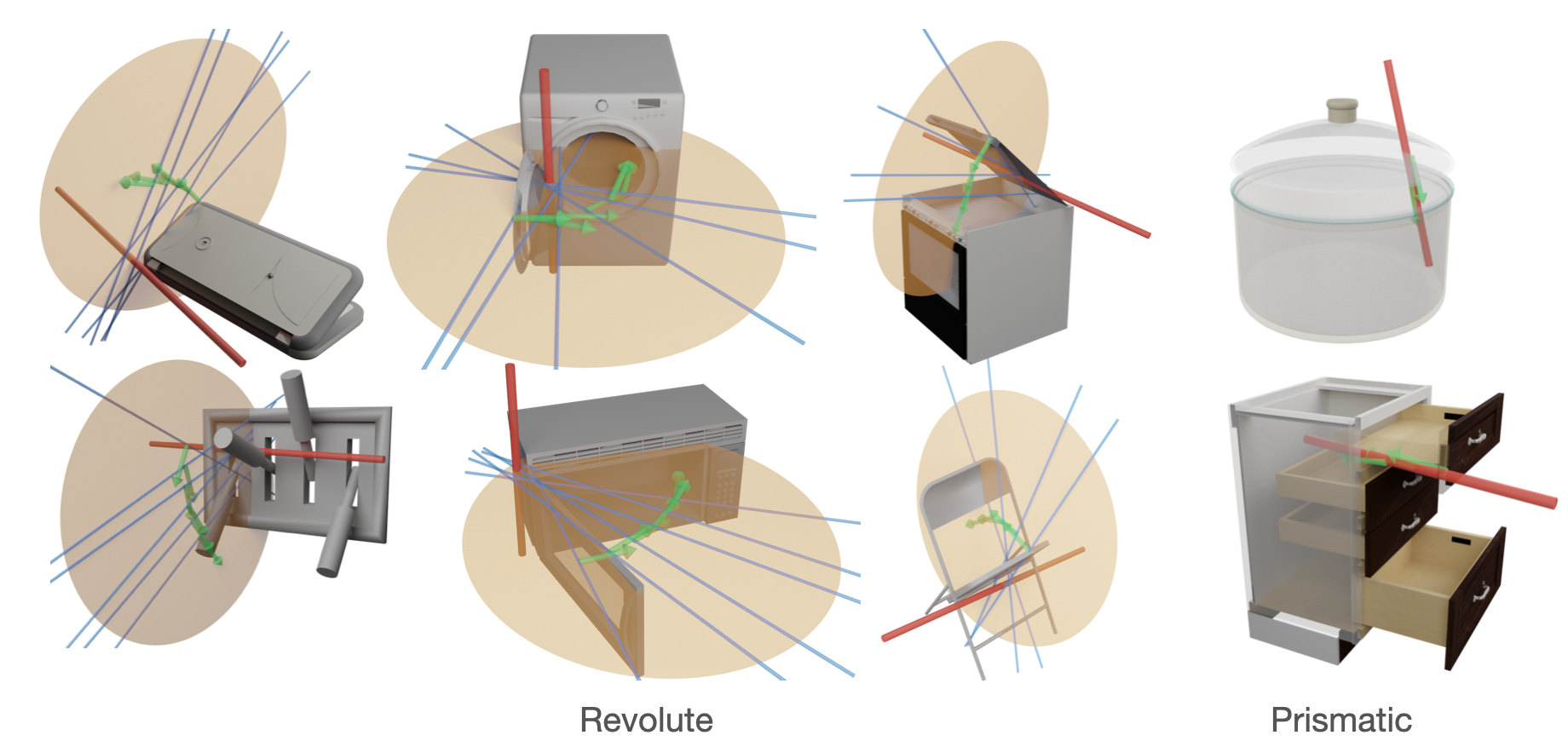
The joint axes (red) are inferred from the actions selected by the learned policy (green), which indicates the system’s implicit understanding about the objects’ articulation structure.
Action Trajectories Executed by Real Robot
Open microwave
Close microwave
Goal-conditioned Manipulation with Real-world RGB-D Images.
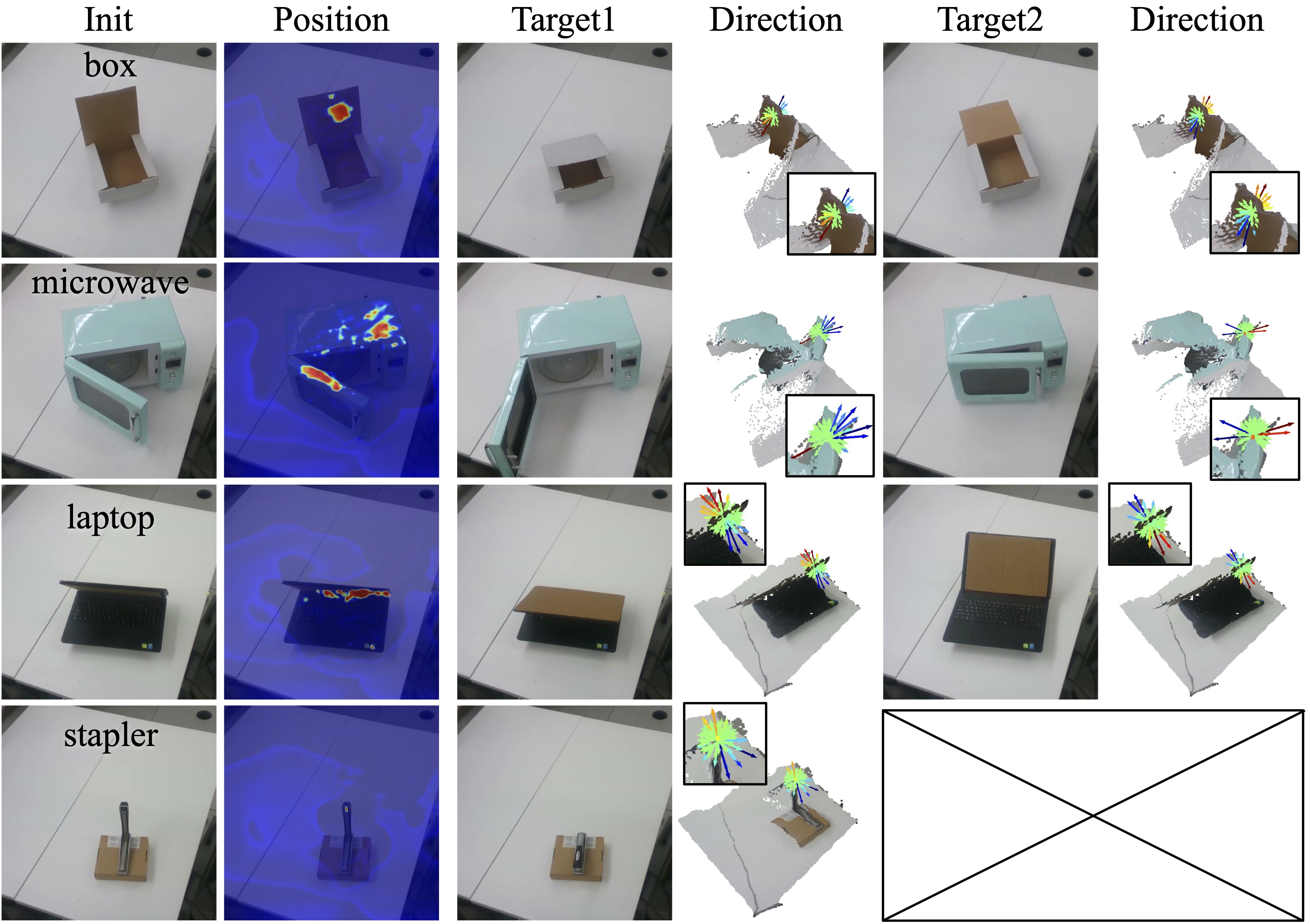
we directly test the trained model trained in simulation on real-world RGB-D images for various objects. For each object, we visualize the inferred action position and direction for two different target states. To move toward the goal, the policy selects the action with the largest distance prediction and a negative AoT label (the longest blue arrow) to execute. This result demonstrates that the trained model is able to infer reasonable grasping positions and suitable action directions for different objects and goal conditions.
Acknowledgements
This work was supported by National Science Foundation under CMMI-2037101 and Amazon Research Award. We would like to thank Google for the UR5 robot hardware.
Contact
If you have any questions, please feel free to contact Zhenjia Xu.